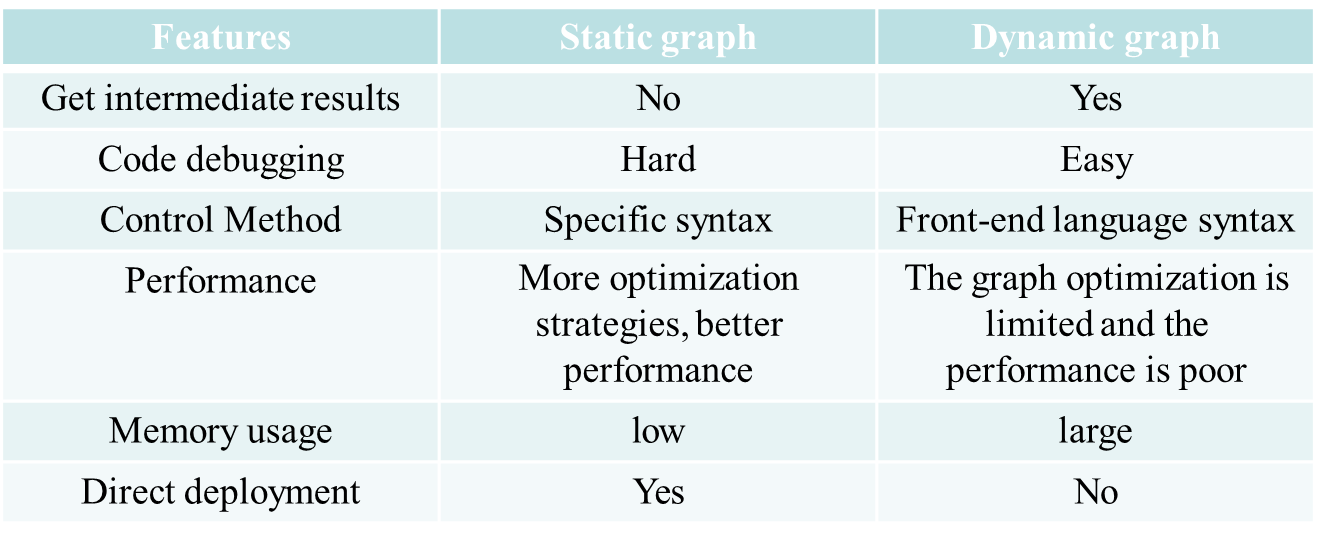
A static graph is one that defines the entire computation graph before performing the computation. When the data is obtained, it is calculated according to the defined calculation graph.
译
静态图是在执行计算之前定义整个计算图的图。获得数据后,根据定义的计算图进行计算。
原
Dynamic graphs, on the other hand, generate computational graphs as they are computed, and the complete graph is known only when the computation is completed.
Problems in processing images with fully connected networks: 全连接网络图像处理中的问题: Too many parameters in the weight matrix -> overfitting 权重矩阵中参数太多->过拟合 Convolutional neural network solution 卷积神经网络解决方案 Local correlation, parameter sharing 本地关联,参数共享
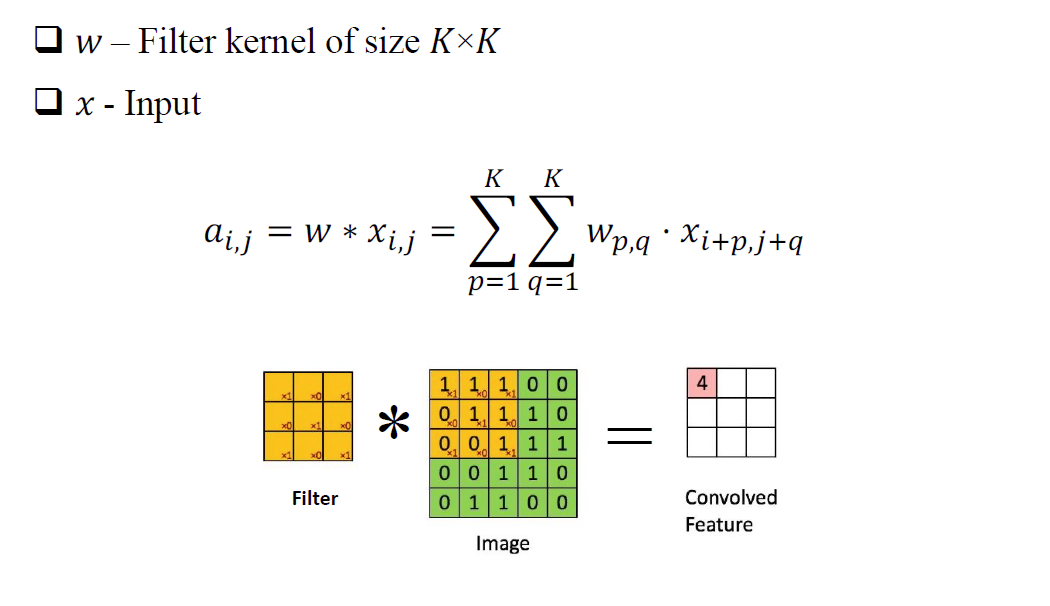
Kernel: also known as receptive field, the sense of convolution operation, intuitively understood as a filter matrix, commonly used convolution kernel size of 3 × 3, 5 × 5 and so on;
Stride: the pixels moved by the convolution kernel at each step when traversing the feature map
译
步幅:在遍历特征图时,卷积核在每一步移动的像素数。步幅决定了卷积操作对输入的采样间隔。
Padding 填充
概念
位置
Padding 填充
PPT p71
原
Padding: the way to deal with the boundary of the feature map. To fill the boundary (generally filled with 0), and then perform the convolution operation, which will make the size of the output feature map the same as the size of the input feature map;
Channel: the number of channels (layers) of the convolution layer.
译
通道:卷积层的通道(层)数
说明
每个通道对输入进行一种特定的卷积操作,多个通道的输出叠加形成最终的输出特征图。
卷积的计算
概念
位置
卷积的计算
PPT p74-p83 Tutorial Solution Q4 & Q5
详见专题子页面:(WIP)
De-convolution 反卷积
概念
位置
De-convolution 反卷积
PPT p84
原
Equivalent to a transposition computation after converting a convolution kernel to a sparse matrix
译
相当于将卷积核转换为稀疏矩阵后的转置计算
说明
卷积是把图片弄成特征图,反卷积是把特征图弄成图片
Dilated/Atrous Convolution 膨胀卷积
概念
位置
Dilated/Atrous Convolution 膨胀卷积
PPT p86
原
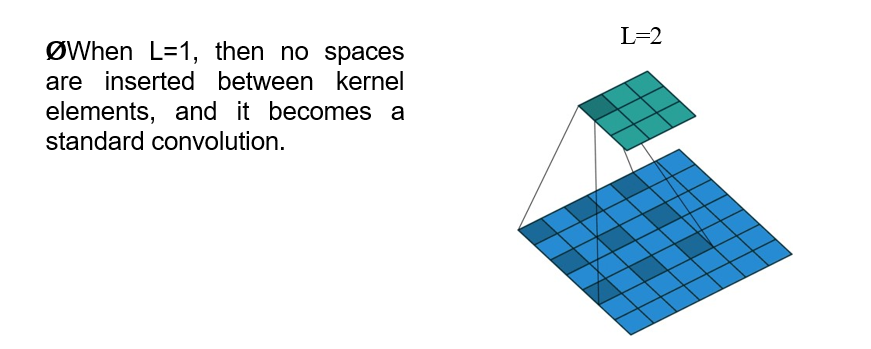
To expand the receptive field, the kernel is “inflated” by inserting spaces between elements inside the convolutional kernel to form a “null convolution” (or inflated convolution), and the kernel to be expanded is indicated by the expansion rate parameter L, i.e., L-1 spaces are inserted between the kernel elements.
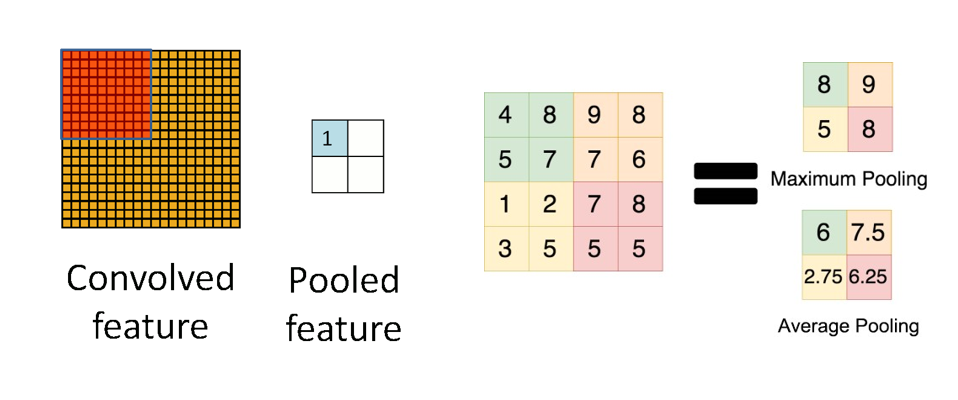
Pooling is used for regions of the image that do not overlap (this is different from the convolution operation)
译
池化操作用于图像中不重叠的区域(与卷积操作不同)
说明
Flatten 压平
概念
位置
Flatten 压平
PPT p90
原
Flatten refers to the process of taking the two-dimensional feature maps produced by the convolution and pooling layers and transforming them into a one-dimensional vector.
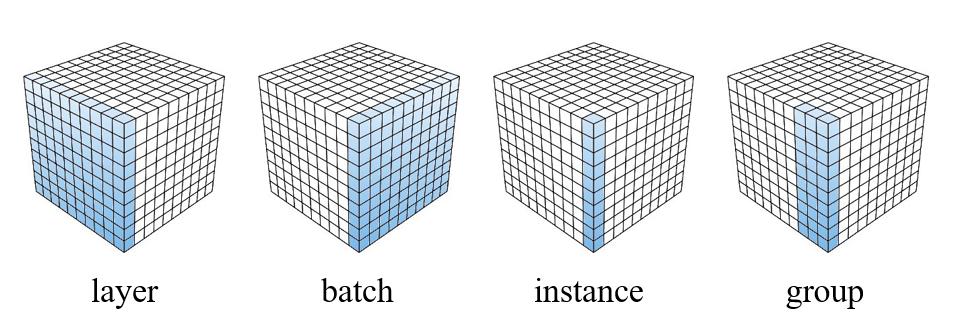
Normalization techniques in Convolutional Neural Networks (CNNs) are crucial for improving training stability, accelerating convergence, and achieving better generalization.
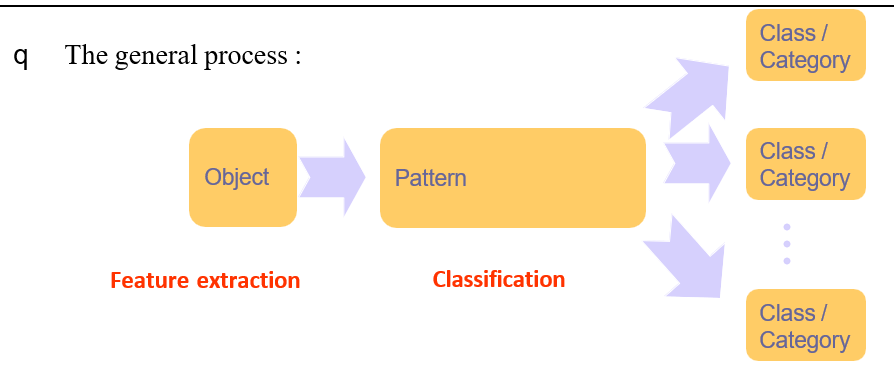
General Framework (Any Hierarchical Model is Deep)(通用框架,任何分层模型都是深度的): 含义: 深度学习中的一般性框架,其中任何具有分层结构的模型都可以被认为是深度模型。深度模型通常包含多个层次的表示学习,这使得模型能够逐渐学习数据的抽象表示。
Q:为什么需要很多层? A:When input has hierarchical structure, the use of a hierarchical architecture is potentially more efficient because intermediate computations can be re-used. DL architectures are efficient also because they use distributed representations which are shared across classes. 当输入具有分层结构时,使用分层架构可能更有效,因为中间计算可以被重复利用。深度学习架构也是高效的,因为它们使用分布式表示,这些表示在不同类别之间是共享的。
Performance Metrics 性能指标
概念
位置
Performance Metrics 性能指标
PPT p126
说明
用以评测模型的准确度和精确度。
True/False Positive/Negative: 模型正确/错误预测正/负类别的数量。
Precision(精确度):TP/(TP+FP) - what percentage of the positive class is actually positive? 表示被模型正确分类为正类别的样本数量与模型所有预测为正类别的样本数量之比。
Recall(召回率): TP/(TP+FN) - what percentage of the positive class gets captured by the model? 表示实际正类别样本中被模型正确分类的数量与所有实际正类别样本的数量之比。
Accuracy(准确率):(TP+TN)/(TP+FP+TN+FN) - what percentage of predictions are correct? 是模型正确分类的图像数量与总图像数量之比。
Confusion Matrix 混淆矩阵
概念
位置
Confusion Matrix 混淆矩阵
PPT p128
说明
Good for checking where your model is incorrect 用于检查模型不正确的地方 For multi-class classification it reflects which classes are correlated 对于多类别的分类,它反映了哪些类型是相关的
Segmentation 分割
概念
位置
Segmentation 分割
PPT p133
原
Segmentation is the process of breaking an image into groups, based on similarities of the pixels
译
分割是根据像素的相似性将图像分成组的过程
说明
Object Recognition 物体识别
概念
位置
Object Recognition 物体识别
PPT p144 Tutorial Solution Q3
原
It is the task of finding and identifying objects in an image or video sequence
译
是在图像或视频序列中寻找和识别物体的任务
说明
步骤: Detection – of separate objects Description – of their geometry and positions in 3D Classification – as being one of a known class Identification – of the particular instance Understanding – of spatial relationships between objects
应用: It is used in various applications, such as autonomous navigation (recognizing obstacles), augmented reality (overlaying digital information on real-world objects), and robotics (identifying objects for manipulation). 它被用于各种应用程序,例如自主导航(识别障碍物)、增强现实(将数字信息覆盖在现实世界的对象上)和机器人(识别用于操作的对象)。

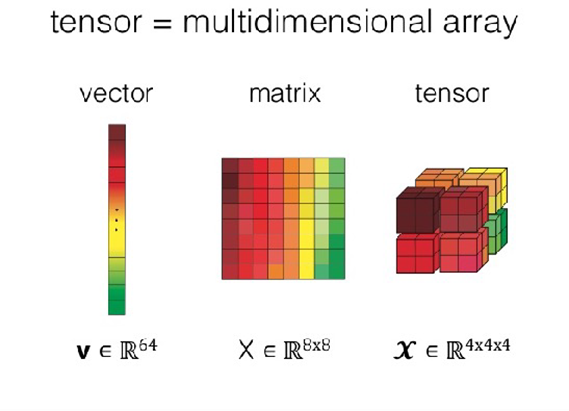

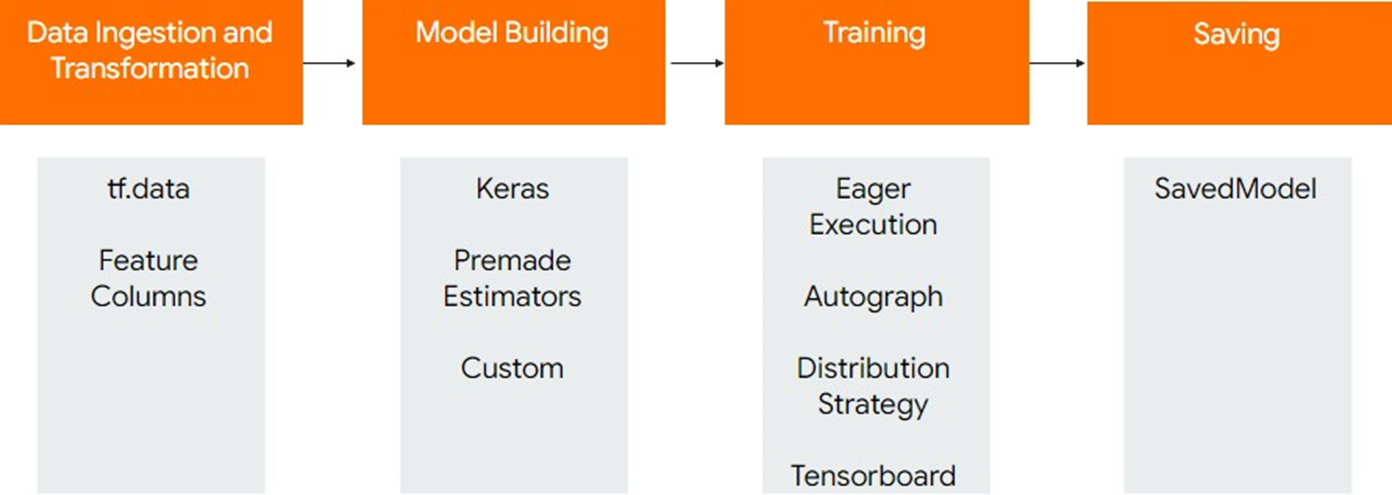 其编程模型可将数字计算(Numeric Computation)过程表达为图表。图表节点为带有数字输入输出的操作,图表的边缘为节点间流动着的张量。
其编程模型可将数字计算(Numeric Computation)过程表达为图表。图表节点为带有数字输入输出的操作,图表的边缘为节点间流动着的张量。