NAT 网络地址转换
NAT = Network Address Translation 背景:ipv4 的可分配地址少,不够用了,且分配不公平。
NAT 的做法:把内部网(家庭网)流出的数据报由同一个 NAT IP 地址发出,将不同的内部 IP 映射到不同的端口号上。对内部网,数据报视作由该 NAT 路由发出。
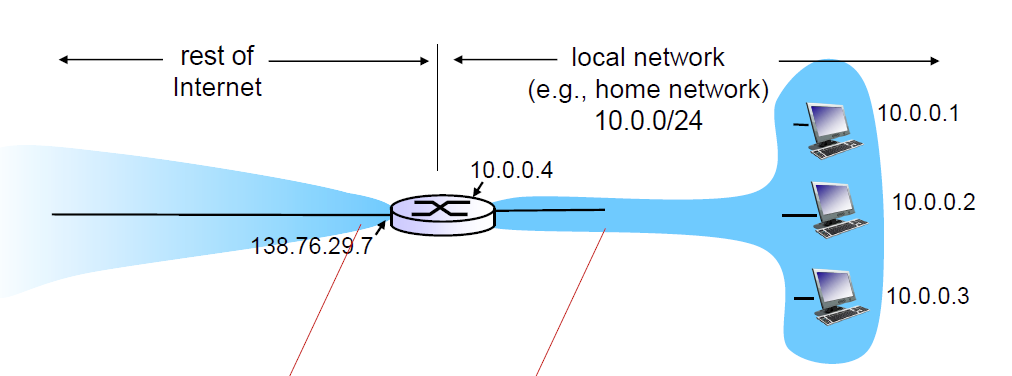 这样一来本地网只需要一个 IP 地址,但对外部网来说:
这样一来本地网只需要一个 IP 地址,但对外部网来说:
- IP 地址可不需要通过 ISP 提供
- 内部设备或地址可随意更换,无需通知外部网
- 可在不调整内部网地址的情况下更换 ISP
- (重要)内部网设备不可从外部显式访问
NAT 的实现:
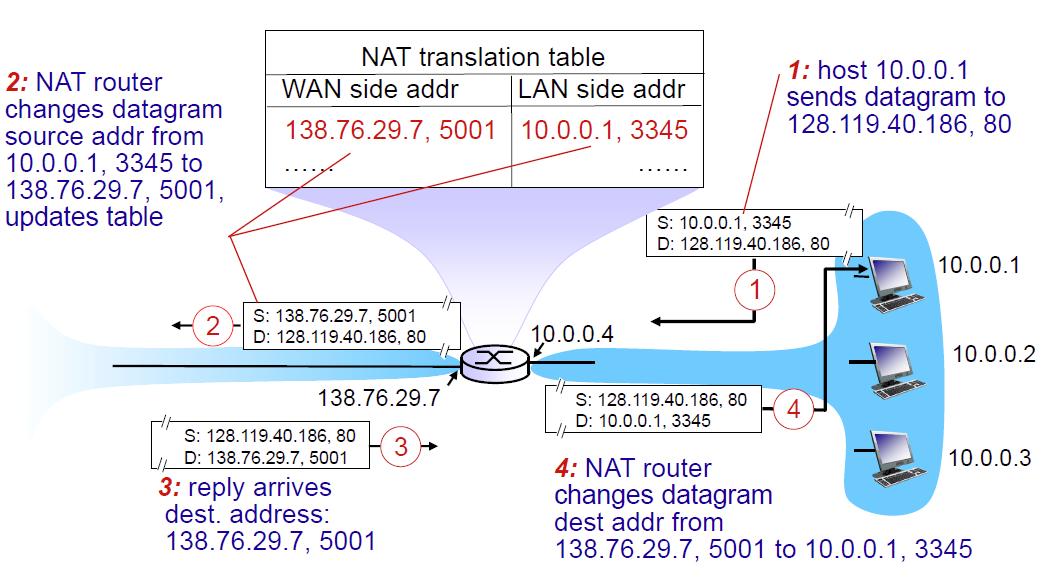
- 对向外流出的数据报: 将数据报的来源 IP 地址替换为 NAT 路由的地址(和映射分配的端口)再发给外网。
- 外部服务器会收到这条请求,其回复的目标 IP 地址会是 NAT 路由的地址和端口。
- 对向内流入的数据报: 将回复中的目标 IP 地址和端口替换为内部网实际主机的 IP 地址和端口
端口号是 16 位的,这说明一次 NAT 可以支持最多六万个同时连接。
 NAT 的争议问题:
NAT 的争议问题:
- 路由器应当只处理第三层(即网络层)的问题。注意,事实上一个 NAT box 应当被视作网络层成员,因为虽然看起来是端口 - 端口通信,但还是第三层的。
- 地址短缺问题应当通过 ipv6 解决
- 端到端复杂性违例:使用 NAT 不符合原先网络层的所有设计,这使得应用开发者在开发应用时必须考虑到有 NAT 存在的情况,不能大规模使用 IP 确认的 P2P 等等。
- 客户端无法访问到 NAT 之后的服务器。
IPv6
提案动机:使用 32 位 IP 地址,能给宇宙里的每一颗沙子都分一个地址用。 一些额外的东西:修改了数据头的格式,可加速处理与转发,改善服务质量(QoS,Quality of Service)。
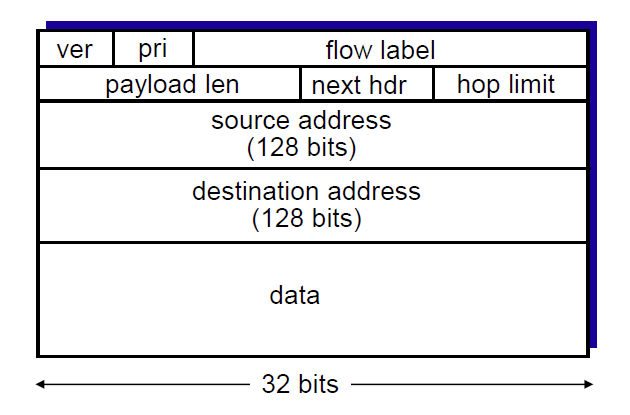
IPv6 数据头
为固定 40 字节大小的头,不允许分片。
- 优先级:指定 flow 中数据报的优先级
- flow 标签:指定数据报是否在同一个 flow 中
- next header:指定上层的数据协议
感觉这东西考的概率不大。
IPv6 的其他变化
- 移除了数据报中的校验和部分:IPv6 认为在链路层和传输层(如 TCP 和 UDP)已经有足够的错误检测机制,所以可以省略 IP 层的校验和,从而减少每个中继节点(hop)处理数据包的时间,提高转发效率。
- 在 IPv4 中,选项(options)是 IP 头部的一部分,可以使头部变得很长,影响数据包的处理速度。而在 IPv6 中,选项被允许存在,但它们不再是头部的一部分,而是通过一个称为“Next Header”(下一个头部)的字段来指示。这意味着选项信息被放在扩展头部中,使基本的 IPv6 头部保持固定长度(40 字节),从而简化了处理。
- 支持 ICMPv6 — ICMP(Internet Control Message Protocol)是用于网络设备间传递控制信息的协议。在 IPv6 中,引入了一个新的版本 ICMPv6。ICMPv6 不仅保留了原有的 ICMP 功能,还增加了一些新的消息类型,比如“Packet Too Big”消息,用于通知发送方数据包太大,需要分片。ICMPv6 还包括多播组管理功能,用于管理多播组的成员关系。
了解即可。
从 IPv4 迁移 & 向下兼容
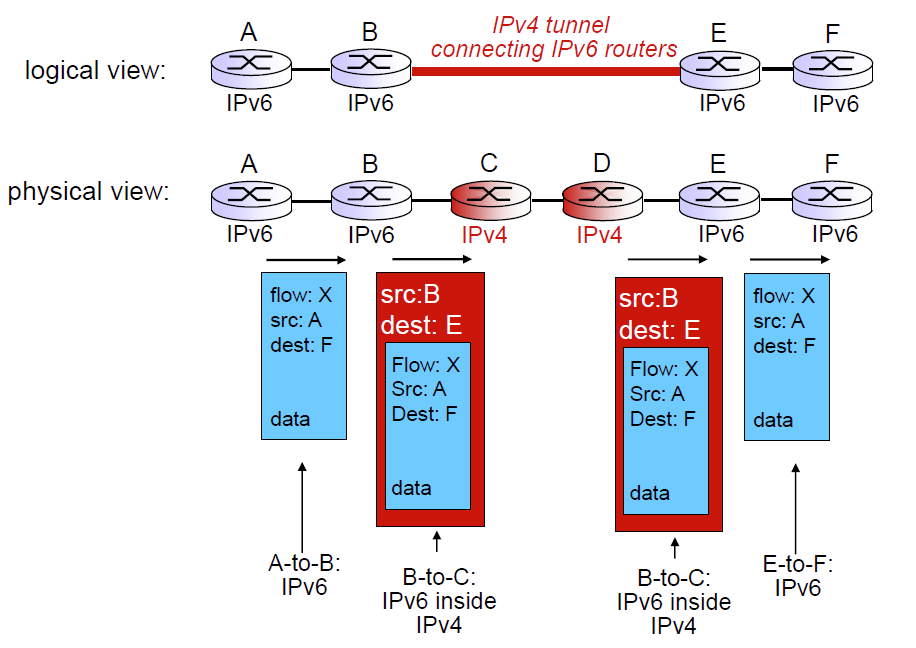
没有办法让所有路由器一夜之间从 IPv4 迁移到 IPv6,因此需要能够在有 IPv4 的路由器的网络中传输 IPv6 数据包。
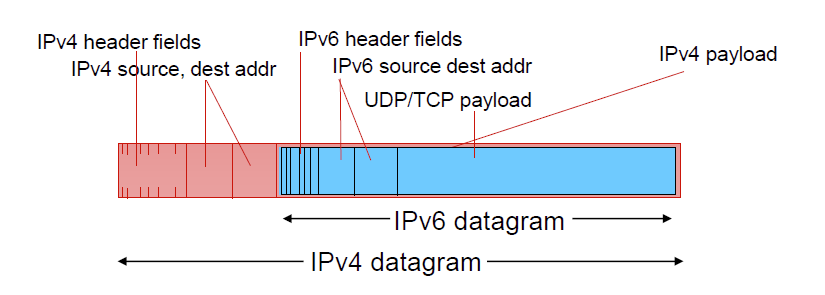
做法:隧道技术(tunneling),将整个 IPv6 数据报封装到 IPv4 的负载 payload 中进行传输
软件定义网络 SDN
传统网络:
- 数据平面通过转发表 forwaring table 根据最长前缀匹配原则进行数据包转发。
- 控制平面会为每个路由器计算出转发表
- 转发表只能根据 IP 地址来决定怎样转发数据包
软件定义网络:更加灵活
- 可使用编程语言 Java、Python 等编写自己的控制算法
- 可根据数据包头的任意部分进行转发。
SDN 数据平面:
- 由控制平面下发一系列“match-action”规则,可对数据包做很多操作(转发、修改数据等等)
- 更加灵活(例如,可单独路由视频数据包,将隐私数据包单独路由,丢弃可以数据包等)
SDN 控制平面:
- 单个中心化的控制器(不是分布式系统)
- 可编程,而非固定的。可以对控制器进行编程。
- 可以创造自己的路由算法然后直接在网络上测试,不用先花大量美金去造个硬件路由器。
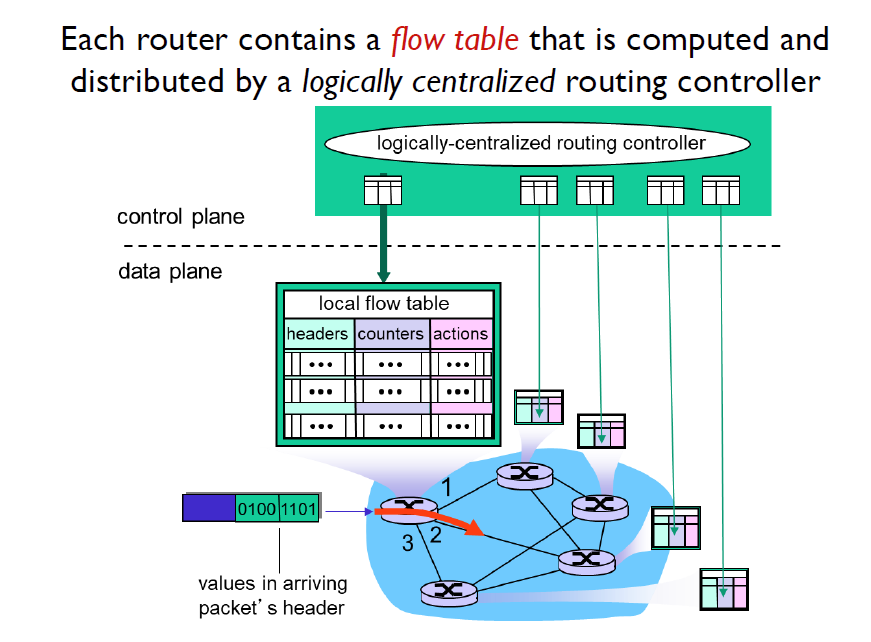
每个路由器会带有一张流向表 flow table,由路由控制器计算并分发出去。
OpenFlow
OpenFlow 是一种 SDN 协议。构成如下:
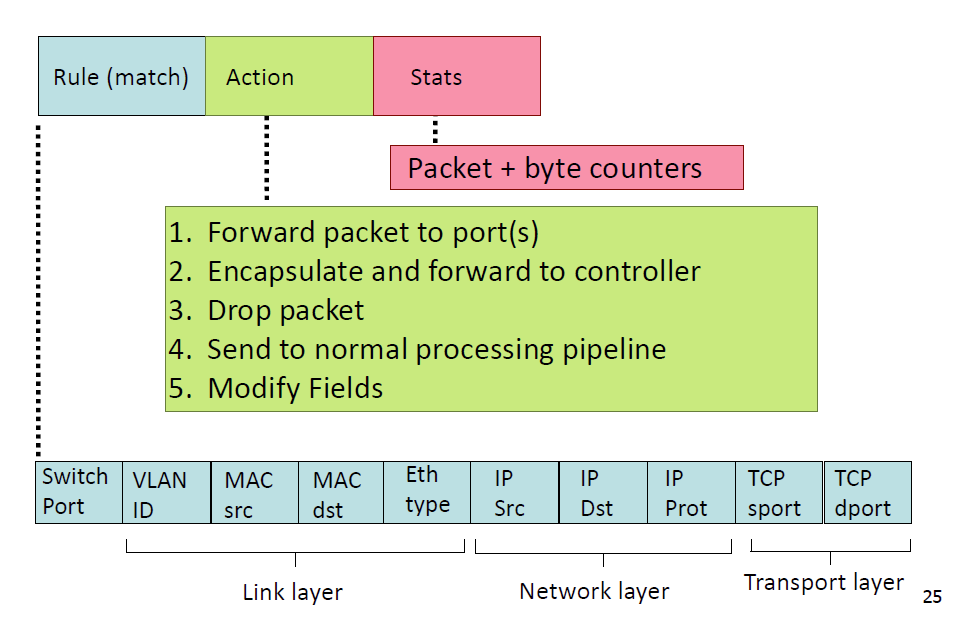 匹配规则 + 动作。
匹配规则 + 动作。

路由协议
找出从发送主机到接收主机间,经过的路由器的“好的”路线。
- 路线:数据包从给定的初始源主机到给定的最终目的主机所经过的路由器序列
- “好”:低成本,速度快,低拥塞。
路由算法分类
信息是否全局? 全局 - 所有路由器都能得到网络全局的拓扑情况和信息等——link state 算法 去中心化 - 路由器知道与自己相连的邻居,到邻居间的连接成本——distance vector 算法
网络结构动态还是静态? 静态:路由随时间变化基本不变化 动态:路由会快速变化,定期更新,响应连接成本变化等。
Link-state 路由算法
使用迪杰斯特拉算法作最短路计算。
这个是个很成块的大题,此处略,见串讲的讲解: 【互联网协议串讲 - 北邮国际学院 (全 3p)】 【精准空降到 1:26:47】 https://www.bilibili.com/video/BV1qy4y177LM/?p=2&share_source=copy_web&vd_source=dac6d447bab3520339763cd9fb9b0afa&t=5207
Distance vector 路由算法
使用 Bellman-Fold 算法。
【互联网协议串讲 - 北邮国际学院 (全 3p)】 【精准空降到 1:40:02】 https://www.bilibili.com/video/BV1qy4y177LM/?p=2&share_source=copy_web&vd_source=dac6d447bab3520339763cd9fb9b0afa&t=6002
自治系统(AS)与路由
AS = autonomous systems
上述的路由算法都太理想化了:认为所有路由器完全相同,所有网络均扁平,这和实际不符。 真实的网络系统:
- 有百万个主机和路由目的地等,你无法在路由表中存储所有目标。
- 只采用 distance vector 方法进行路由表交换会导致大量网络拥塞。
- 互联网是网中之网,每个网络管理员可能希望控制自己网络中的路由规则。
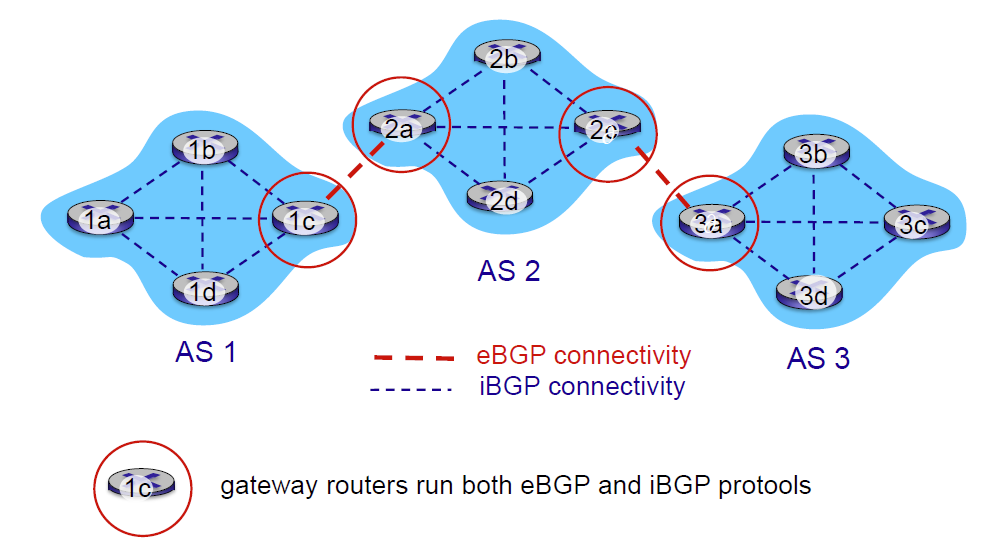
intra-AS 路由(AS 内路由)
- 在同一个 AS 网络内进行路由
- 同个 AS 内的所有路由器必须运行相同协议
- 不同 AS 内的路由可以运行不同协议
- 存在网关路由:在自己 AS 的边缘,和其他 AS 的路由相连接。
inter-AS 路由(AS 间路由)
- 在不同 AS 间路由
- 网关路由器同时做内路由和外路由
考虑 AS 的路由情况,路由表/转发表是有 AS 内和 AS 间的路由算法共同配置决定的。AS 内路由决定 AS 内的路由情况,二者共同作用决定外部目标的路由情况。
intra-AS 路由(AS 内路由)
IGP = interior gateway protocols 内部网关协议 常见的内部路由协议:
- RIP: Routing Information Protocol
- 咱们讲的是这个 -> OSPF: Open Shortest Path First (IS-IS protocol essentially same as OSPF)
- IGRP: Interior Gateway Routing Protocol (Cisco proprietary for decades, until 2016)
OSPF 协议采用 link state 算法:网络间会分发 link state 数据包,得到每个节点的拓扑结构,然后基于迪杰斯特拉算法进行计算路由。 路由器会向整个 AS 内的所有路由器广播(flood)通告 OSPF 数据包,这一步是直接通过 IP 协议而非 TCP 或 UDP。
IS-IS 路由协议和 OSPF 基本一样。
高级特性:
- 安全性:所有 OSPF 消息均需认证
- 允许多个相同成本的路径(RIP 不支持)
- 支持不同 ToS 的链路成本指标
- 集成的单播和多播支持。MOSPF(多播 OSPF)利用与标准 OSPF 相同的拓扑数据库来计算多播路由信息。
- 在大型网络中,OSPF 可以采用分层结构,通过划分区域来提高网络的可扩展性和管理效率。
inter-AS 路由(AS 间路由)
任务:
需要知道哪个目的地能够到达 AS2,哪能到达 AS3
要把这个信息告诉当前 AS1 内的所有路由器
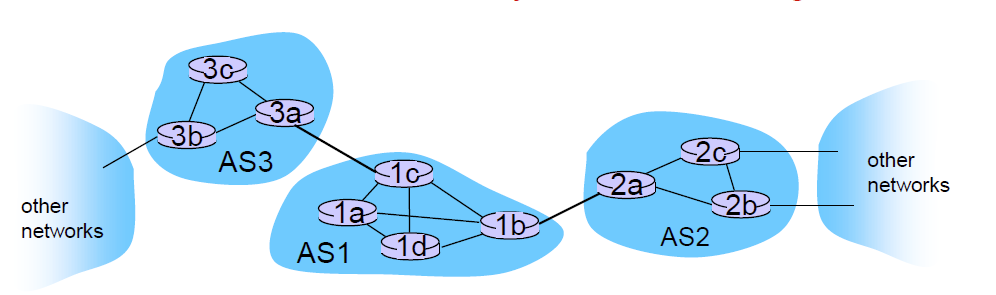 BGP = Border Gateway Protocol
BGP = Border Gateway ProtocoleBGP:从相邻的 AS 获取子网可达性信息。eBGP(外部 BGP)用于在不同的自治系统(AS)之间交换路由信息。通过 eBGP,AS 可以从相邻的 AS 获取到哪些子网是可达的。
iBGP: 将可达性信息传播给所有 AS 内部的路由器。iBGP(内部 BGP)用于在同一个自治系统内部传播路由信息。这样,AS 内部的所有路由器都可以知道哪些子网是可达的。
BGP 不仅仅是传递路由信息,它还要根据这些信息和预先设定的策略来选择最佳路由。所谓“好”路由通常指的是更优的路径,这可以基于多种因素,例如路径长度、路由策略、带宽等。
通过 BGP,某个子网可以向整个互联网公告它的存在。这意味着其他 AS 可以通过 BGP 了解该子网的可达性,并据此进行路由选择。